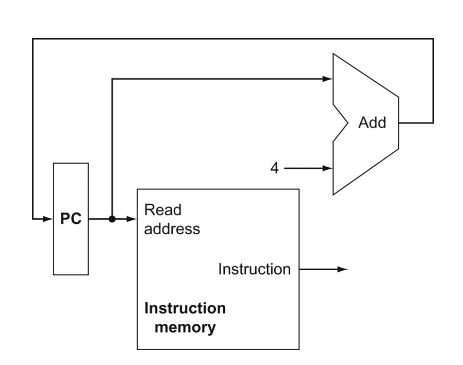
CPU의 Memory Access (MEM) 단계는 실행 중인 명령어가 메모리와 상호작용하는 단계로, 주로 데이터의 읽기(Load)와 쓰기(Store) 작업이 이루어집니다. 이 단계는 메모리 시스템과의 연결을 통해 데이터를 처리하며, 프로그램의 데이터 흐름에 중요한 역할을 합니다.
Memory Access (MEM) 단계의 주요 기능
- 데이터 읽기 (Load)
- LW(Load Word) 명령어와 같은 메모리 읽기 작업을 처리합니다. 이 과정에서 계산된 주소를 사용하여 메모리에서 데이터를 읽어와 레지스터에 저장합니다.
- 예를 들어, 특정 레지스터에서 베이스 주소를 가져오고, 오프셋을 더해 최종 메모리 주소를 계산한 후, 해당 주소에서 데이터를 읽습니다.
- 데이터 쓰기 (Store)
- SW(Store Word) 명령어와 같은 메모리 쓰기 작업을 처리합니다. 이 과정에서는 데이터를 메모리에 저장하기 위해 주소를 계산하고, 해당 메모리 주소에 데이터를 기록합니다.
- 메모리 주소는 일반적으로 레지스터 값에 오프셋을 더하여 결정됩니다.
- 메모리 접근 지연
- 메모리 접근은 CPU와 메모리 간의 대기 시간(latency) 때문에 시간이 걸릴 수 있습니다. 이로 인해, CPU 파이프라인에서의 성능 저하를 방지하기 위해 데이터 포워딩, 캐시 메모리, 버퍼 등의 기술이 활용됩니다.
- 메모리 일관성 유지
- 다중 프로세서 시스템에서는 메모리 일관성을 유지하는 것이 중요합니다. 메모리 접근 단계에서 이와 관련된 프로토콜이나 메커니즘이 필요할 수 있습니다.
- 캐시 메모리 활용
- 메모리 접근 단계에서 캐시 메모리를 활용하여 메모리 접근 속도를 개선할 수 있습니다. CPU는 캐시를 먼저 검사하고, 캐시에서 데이터를 찾지 못한 경우에만 메인 메모리에 접근합니다.
MEM 단계의 흐름
- EX 단계에서 계산된 주소가 MEM 단계로 전달됩니다.
- 이 주소를 기반으로 메모리에서 데이터 읽기 또는 쓰기가 수행됩니다.
- 읽기 작업의 경우, 읽은 데이터는 레지스터에 저장됩니다. 쓰기 작업의 경우, 데이터를 메모리로 전송합니다.
- 작업이 완료된 후, 다음 단계인 Write Back (WB) 단계로 결과가 전달됩니다.
관련 설계 고려 사항
- 데이터 위험 (Data Hazard): MEM 단계에서의 데이터 위험은 주로 Load-Use 위험과 관련이 있습니다. 즉, Load 명령어로 읽어온 데이터가 다음 명령어에서 사용될 경우, 이를 해결하기 위한 포워딩 또는 스톨을 적용해야 합니다.
- 메모리 대역폭: MEM 단계의 성능은 메모리 대역폭에 의존하므로, 설계 시 메모리 접근 속도를 최적화하는 것이 중요합니다.
- 동기식 및 비동기식 메모리: 메모리 접근이 동기식인지 비동기식인지에 따라 설계가 달라질 수 있습니다. 비동기식 메모리는 대기 시간이 더 길 수 있지만, CPU의 파이프라인을 보다 원활하게 운영할 수 있습니다.

* https://cs.middlesexcc.edu/~schatz/csc264/handouts/mips.datapath.html
'CPU ARCHITECTURE1 > CPU' 카테고리의 다른 글
| 06. CPU DATA PATH - R-Type (Register Write) (0) | 2024.09.30 |
|---|---|
| 05-5. Write Back(WB) (0) | 2024.09.30 |
| 05-3. Execute(EX) (0) | 2024.09.30 |
| 05-2. Instruction Decode (ID) (0) | 2024.09.30 |
| 05-1. Instruction Fetch(IF) (0) | 2024.09.30 |