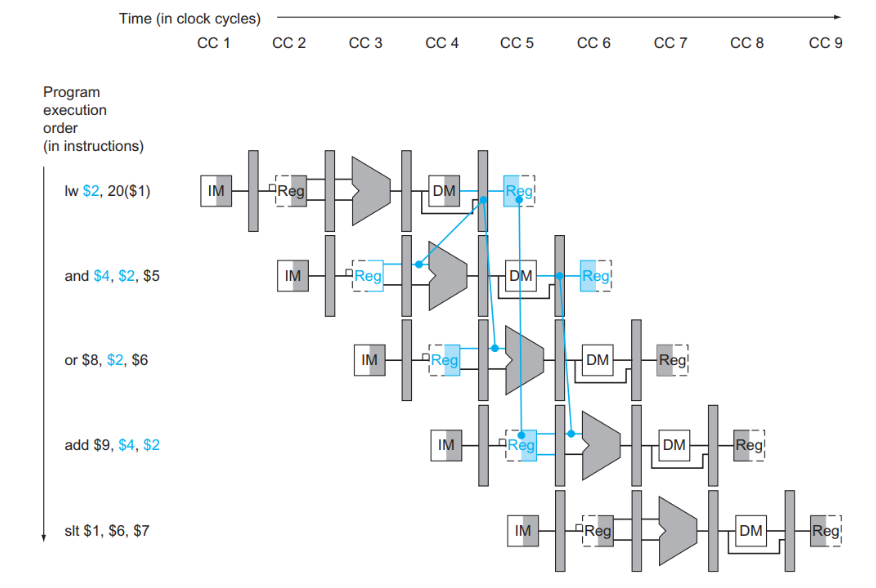
1. 데이터 포워딩 (Forwarding)
정의: 데이터 포워딩은 ALU의 출력 결과를 직접 다음 명령어의 입력으로 연결하여, 데이터가 필요할 때 바로 사용할 수 있도록 하는 기술입니다. 이 방법은 데이터 해저드를 줄이고 파이프라인의 효율성을 높이는 데 매우 효과적입니다.
작동 원리:
- ALU는 명령어가 실행되는 동안 결과를 계산하고, 이 결과를 레지스터에 쓰기 전에 다음 명령어가 사용할 수 있도록 포워딩합니다.
- 예를 들어, 두 개의 명령어가 있을 때:
sub 명령어는 $t1의 값을 필요로 합니다. add 명령어가 결과를 레지스터에 쓰기 전에 ALU의 출력을 직접 sub 명령어로 포워딩하여 $t1을 사용할 수 있게 합니다.assembly코드 복사add $t1, $t2, $t3 # $t1 = $t2 + $t3 sub $t4, $t1, $t5 # $t4 = $t1 - $t5
장점:
- 파이프라인의 지연을 최소화하고 성능을 극대화할 수 있습니다.
- 레지스터에 쓰기 사이클을 줄여 전체 사이클 수를 감소시킵니다.


2. 스톨 (Stall)
정의: 스톨은 명령어 실행 사이에 지연 사이클을 삽입하여, 필요한 데이터가 준비될 때까지 기다리는 방법입니다. 이 방식은 데이터 해저드를 해결하기 위해 간단한 접근 방식이지만, CPU의 성능을 저하시킬 수 있습니다.
작동 원리:
- 파이프라인에서 특정 명령어가 이전 명령어의 결과를 필요로 할 때, 스톨을 발생시킵니다.
- 예를 들어, 위의 명령어를 사용할 경우, add 명령어가 끝나기 전에 sub 명령어가 실행되려고 하면, 스톨 사이클을 삽입하여 sub가 실행되기 전에 add가 완료되도록 합니다.
장점:
- 구현이 간단하고, 특정 상황에서 안전하게 동작할 수 있습니다.
단점:
- 스톨을 사용하면 CPU의 파이프라인이 비활성 상태가 되어 성능이 저하됩니다. 특히 여러 번의 스톨이 발생할 경우, 전체 성능에 심각한 영향을 미칠 수 있습니다.
- 예를 들어, 두 개의 명령어 사이에 1~2 사이클의 지연을 추가하게 되어, 프로그램의 실행 속도가 느려질 수 있습니다.
결론
- 데이터 포워딩은 성능을 유지하면서 데이터 해저드를 해결하는 데 매우 효과적입니다. 현대 CPU 설계에서 일반적으로 사용되는 방법입니다.
- 스톨은 간단하고 안전한 방법이지만, 성능 저하를 초래할 수 있으므로 가능하면 데이터 포워딩과 함께 적절히 조합하여 사용해야 합니다.
이 두 가지 방법을 통해 데이터 해저드를 효과적으로 관리하고 CPU의 파이프라인 성능을 최적화할 수 있습니다.
* https://hackmd.io/@yW7HKRexRASTmH3kBDXQpQ/Sy395BDg5#data-hazards27
'CPU ARCHITECTURE1 > CPU' 카테고리의 다른 글
| 15. Hazard (0) | 2024.09.30 |
|---|---|
| 14. Active at same clock (0) | 2024.09.30 |
| 13. Pipeline Register (0) | 2024.09.30 |
| 12. Advantage of Pipeline (0) | 2024.09.30 |
| 11. CPU DATA PATH - J - Type(JUMP) (0) | 2024.09.30 |